计算机系统小常识(下)
链接
编译的全过程
cpp预处理器,main.cpp$\rightarrow$main.i(ASCII 中间文件)。cc1编译器,main.i$\rightarrow$main.s(ASCII 汇编语言文件)。as汇编器,main.s$\rightarrow$main.o(可重定位目标文件)。ld静态链接器,main.o,sum.o$\rightarrow$prog(可执行文件)。
静态链接器需要完成以下两个任务:
- 符号解析 目标文件定义和引用了符号(函数、全局变量、静态变量等),符号解析将每个定义和引用联系在一起。
- 重定位 编译器和汇编器生成地址从 $0$ 开始的数据和代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节。
看到后面就知道具体是什么东西了。
目标文件
分为
- 可重定位目标文件。包含二进制代码和数据,可以在链接时和其他可重定位目标文件合并创建一个可执行目标文件。
- 可执行目标文件。可以直接被复制到内存上执行。
- 共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态加载进内存并链接。
目标文件按照一定的格式来组织。在 Windows 系统中为可移植可执行格式(Portable Executable,PE),Mac OS-X 使用 Mach-O 格式,现代 Linux 和 Unix 使用可执行可链接格式(Executable and Linkable Format,ELF)。
可重定位目标文件
多文件编译时,称一个目标模块为 .o 文件中的字节序列,目标文件为实际上磁盘中的文件。
ELF 的格式
- ELF 头 现有 16 字节的序列描述生成文件的系统的字大小、字节顺序,后接 ELF 头大小、目标文件类型、机器类型、节头部表的文件偏移,节头部表中条目的大小和数量。
- 节 夹在 ELF 头和节头部表之间的字节序列。其位置和大小由节头部表描述。典型的 ELF 文件包含下面的节
.text机器代码。.rodata只读数据,比如printf中的字符串常量和跳转表等。.data已初始化的全局和静态变量。.bss未初始化的全局和静态变量,以及初始化为 $0$ 的全局和静态变量。注意在可重定位目标文件中这一节只是占位符不占用空间,因为初始化为 $0$ 不需要额外信息。.symtab符号表,存放定义和引用的函数和全局变量的信息。(不包含局部变量,仅声明的函数,.rodata).rel.text链接时可能需要修改的.text中的位置表。.rel.data被模块引用或定义的所有全局变量的重定位信息。(已初始化的全局变量,其初值为外部全局变量或函数的地址,则可能会被修改)。.debug调试符号表,包含局部变量和类型、全局变量、原始文件。(仅-g时生成).line原始程序行号和机器指令之间的映射。(仅-g时生成).strtab字符串表,包含.symtab、.debug中的符号表和节头部中的节名字。
符号和符号表
每个可重定位目标模块 $m$ 都有一个符号表,包含 $m$ 中定义和引用的符号的信息。符号分为以下三种:
- 由模块 $m$ 定义并能被其他模块引用的全局符号,称作全局链接器符号(非静态的函数和全局变量)。
- 由其他模块定义并被 $m$ 引用的全局符号,成为外部符号(其他模块中非静态的函数和全局变量)。
- 只被模块定义和引用的局部符号(带
static属性的函数和全局变量)。这些符号对其他模块不可见。
过程变量(即平常语境下的“局部变量”)在栈中,所以链接器不需要处理。函数中的 static 类过程变量不在栈中而是在 .data 或者 .bss 中,但是可以重名,这时编译器将向汇编器输出两个不同名字的局部链接器符号(比如 x.1 和 x.2 状物)。
符号表的格式为:
1 | typedef struct { |
section 可以是一些整数(1 表示 .text,3 表示 .data,etc.),也可以是一些特殊常数,称作伪节,伪节在节头部表中没有条目。
ABS不该被重定位的符号。UNDEF未定义的符号。COMMON未被分配位置的未初始化数据目标。
COMMON 和 .bss 有一点区别,在 GCC 中一般未初始化的全局变量去 COMMON,未初始化的静态变量和初始化为 $0$ 的全局或静态变量去 .bss。但是这是一个很傻逼的历史遗留问题,可以用 fno-common 来让所有东西都去 .bss。在后面我们会看到为什么要留着一个 COMMON。
符号解析
C++ 和 Java 发生重载的时候,编译器将类中每个重载函数的名字改成函数名
__类名字符数加类名加参数表。比如Foo::bar(int, long)将会被改成bar__3Fooil。这个过程称作重整,反向过程称作恢复。
定义函数和已经初始化的全局变量为强符号,未初始化的全局符号为弱符号。
当符号重名时,有如下规则:
- 强符号不能重名。
- 一个强符号和多个弱符号重名,选择强符号。
- 有多个弱符号,则任选一个。
如果遇到弱符号,编译器就会被放入 COMMON 伪节。但是如果多个模块里面发生了无意识的符号重名,就会寄的很惨,所以怀疑此类错误时一般打开 fno-common,这样如果定义了多个弱符号也会报错。
静态库
为了引用标准函数,有几种极端的办法:
- 让编译器生成标准函数代码。但这会显著增加编译器的复杂性。
- 每次链接都与定义了全体标准函数的模块(e.g.
libc.o)链接。但这样很费内存。 - 为每个函数创建一个可重定位文件。但是这样你需要
include大量的东西。
解决的办法是把若干可重定位文件封装成一个静态库文件(.a,存档文件,一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置)。
通过 AR 工具来创建一个静态库。
1 | gcc -c addvec.c mulvec.c |
用
1 | gcc -static -o prog main.o ./libvector.a |
或者等价地
1 | gcc -static -o prog main.o -lvector |
来进行链接。-static 参数指示构建一个完全链接的可执行目标文件。
链接器解析引用流程
从左到右扫描出现在命令行上的目标文件和存档文件,维护三个集合:可重定位目标文件集合 $E$,未解析符号集合 $U$,已定义符号集合 $D$。
- 如果是目标文件那么其会被加入 $E$,然后根据内容修改 $U, D$。
- 如果是存档文件,那么链接器将尝试匹配 $U$ 和存档文件成员中的定义。如果对上了,就将该成员加入 $E$,然后修改 $U, D$,重复直到 $U, D$ 都不再变化。
如果 $U$ 非空则发生链接错误,否则继续进行重定位之类的工作。
从上述过程中看出静态库应该被放在命令的最后。且如果有相互依赖关系,需要在命令行中重复库或者合并相互依赖的库。
Example.
libx.a 依赖 liby.a 中的目标文件,而 liby.a 也依赖 libx.a 中的目标文件。那么此时命令应当是
1 | gcc foo.c libx.a liby.a libx.a |
重定位
过程大致分成两段:
- 重定位节和符号定义 合并所有相同类型的节,给每条指令和全局变量分配唯一的运行时内存。这部分比较 trivial。
- 重定位节中的符号引用 修改符号引用,使其指向正确的地址。
重定位条目
回忆之前讲的 rel.text 和 rel.data 两节,当汇编器遇到一个最终位置未知的符号引用就往里面塞一个重定位条目。一个重定位条目结构为
1 | typedef struct { |
重定位类型有 $32$ 中,我们只关心两种基本的类型:
R_X86_64_PC32重定位一个 $32$ 位 PC 相对地址的引用。R_X86_64_32重定位一个 $32$ 位绝对地址的引用。
这两种重定位模型假设代码和数据加起来不超过 $2$ GB,因此都可以用 $32$ 位相对地址表示。
重定位符号引用
假设现在已经做完了重定位节和符号定义。那么重定位算法大概是:
- 对于节 $s$($s = \texttt{.data} / \texttt{.text}$),设其地址为
ADDR(s)。 - 考察节 $s$ 的重定位条目表中的每一项 $r$。
- 找到对应的位置
refptr = s + r.offset。 - 若为 PC 相对寻址
r.type == R_X86_64_PC32,找到该位置的运行时地址ADDR(s) + r.offset,然后修改目标位置*refptr = (unsigned)(ADDR(r.symbol) + r.addend - refaddr) - 若为绝对寻址
r.type == R_X86_64_32,则直接改*refptr = (unsigned)(ADDR(r.symbol) + r.addend)。
- 找到对应的位置
回忆相对寻址时用的是下一条指令开始的地址,所以在 R_X86_64_PC32 时,addend 是重定位目标位置的开始地址减去下一条指令的开始地址。
一定记住 x86_64 是小端法,所以你看到重定位完符号引用之后的数字是倒过来的。
可执行目标文件
可执行目标文件对比可重定位目标文件的差距是:
- ELF 头 还需要包括程序的入口点。
- 段头部表 描述段的信息。描述一个段需要
off目标文件中的偏移。vaddr / paddr内存地址。align对齐要求。对于任意的段,链接器必须使得其起始地址(段中第一个节的起始地址)满足vaddr % align = off % align。filesz目标文件中的段大小。memsz内存中的段大小。memsz和filesz不总是一样的。回忆.bss区不占空间,于是.data的memsz比filesz多出来的部分将会被用来开.bss节。flags访问权限,可以是r-x、rw-之类的。
.init节 定义了一个_init函数,程序的初始化代码会调用它。- 没有
.rel节 因为已经重定位完了。
align的必要性在后面虚拟内存一节才被揭示。
ELF 头,段头部表,.init,.text,.rodata 是只读内存段;.data,.bss 是读写内存段;.symtab,.debug,.line,.strtab,节头部表之类的属于不加载到内存的符号表和调试信息。
可执行文件运行时被加载器(loader)按照段头部表的指示。复制到内存中去执行。只读代码段从 0x400000 开始向上增长,接下来是读/写段、向上增长的堆、共享库内存、向下增长的栈(从 $2^{48} - 1$ 开始向下增长)、对用户不可见的内核代码。运行时首先执行 _start 函数,_start 调用 __libc_start_main,此函数初始化执行环境然后调用用户层的 main 函数,处理 main 的返回值并在需要的时候把控制返回给内核。
动态链接
动态链接有两方面动机:
- 让程序能够 follow 标准库的更新,不需要重新链接。
- 减少高频率使用的库(
printf,scanf等)的内存占用。
用如下办法创建一个动态链接库
1 | gcc -shared -fpic -o libvector.so addvec.c multvec.c |
其中 -fpic 指示生成位置无关代码。(在下一小节解释)
链接除了可以手动编译:
1 | gcc -o prog main.c ./libvector.so |
之外还可以使用一些神秘函数,编译的使用要加 -rdynamic 选项,-ldl 应该是链接上动态链接器的代码
1 | gcc -rdynamic -o prog main.c -ldl |
函数有下面三个,直接看肯定看不懂在干什么,推荐先看后面的代码。
1 |
|
如果成功则返回一个 handle。
可以在运行时加载和链接共享库 filename。flag 可以是
RTLD_NOW立即解析外部符号引用。RTLD_LAZY等到执行库中代码时再解析。RTLD_GLOBAL前面两个参数可以或上这东西。
将用已经用 RTLD_GLOBAL 打开的库解析 filename 中的外部符号。
1 | void *dlsym(void *handle, char *symbol); |
查询一个共享库里面是否有 symbol。成功返回符号地址,否则返回 NULL。
1 | int close(void *handle); |
如果没有其他共享库还在使用这个共享库,就将其关闭。成功返回 $0$,否则返回 $1$。
1 | const char *dlerror(void); |
返回前面几个函数调用最近发生的错误。没出错返回 NULL。
使用方法为(在上面编译的 main.c 中写主函数):
1 | int main() { |
位置无关代码
显然为了保持动态库的特性,一个动态库必须被能够被复制到共享库内存中的任何位置都能正常运行。这需要将代码编译成位置无关代码(可以加载但是无需重定位)。那么对库内部的引用可以简单地解决(使用 PC 相对寻址),但是外面的模块调用库函数则需要解决两方面问题:
PIC 数据引用
注意代码段和数据段之间的距离总是一个常量,那么可以在
.data区的最前面定义一个全局偏移量表 GOT,每个全局数据目标都会在 GOT 里面有一个八字节条目,和一个重定位记录。动态链接时链接器会让 GOT 里面的条目指向正确的地址。在引用一个外部符号时,先拿着 PC 找到对应的 GOT 表项,然后找到正确的位置。你可能会编译出这样的代码:1
2mov 0x2008b9(%rip), %rax # 拿着 PC 找到 GOT 表项
addl $0x1, (%rax) # 拿着 GOT 表项找到正确的引用地址PIC 函数调用
显然库里面的函数只会用很少一部分,所以正常的想法是做某种 lazy load。
这里需要用到两个数据结构,GOT 和 PLT。回忆 GOT 是一个每个 entry 为 8 字节整数的数组。而 PLT 是一个每个 entry 32 字节代码的数组。
GOT 数组
GOT[0]存的是.dynamic节开始的位置,不知道是干什么的。GOT[1]存的是重定位条目的地址。(给动态链接器的参数)GOT[2]存的是动态链接器的地址。其余项一开始都指向对应的 PLT 表项的第二行,在被调用第一次之后会被链接器改成实际上的引用地址。
PLT 数组
PLT[0]是下面两行:1
2pushq *GOT[1]
jmpq *GOT[2] # 运行动态链接器,它会拿着栈里面的参数去做重定位PLT[1]是一个调用__libc_start_main,这里我们不关心。PLT[2]开始,都是描述一个外部引用的,下面三行:1
2
3
4jmpq *GOT[4] # 第一次调用这玩意会直接传到下一行,下一次就会传到正确的引用位置
pushq $0x1 # 把这个外部引用的 id 推到栈里
jmpq 4005a0 # 4005a0 是 PLT[1] 的第一行代码,现在动态链接器会拿着正确的参
# 数去找这个外部引用的实际位置,完成重定位目标模块里面的函数调用就被编译成
call对应的 PLT 的第一行。
异常控制流
异常
在执行某指令 $I_{\rm curr}$ 时,处理器检测到发生一个事件,就会拿着事件的编码在一个称作异常表(这个表的地址可以在 CPU 中的异常表基址寄存器里找到)的结构中找到处理此事件的异常处理程序的代码,执行完毕后选择:
- 重新执行 $I_{\rm curr}$。
- 执行下一条指令 $I_{\rm next}$。
- 终止该程序。
这样发生的控制流的突变,称作异常。
回忆控制流中发生的跳转还有一种形式是函数调用,但是异常和函数调用有如下区别:
- 不一定返回到下一条指令。
- 可能在栈中压入包含当前条件码的
EFLAGS寄存器和其他内容压栈。 - 所有东西都会被压到内核栈上。
- 异常处理程序运行在内核模式下。
异常可以分为
| 类型 | 原因 | 同步 / 异步 | 返回行为 | 例子 |
|---|---|---|---|---|
| 中断 | I/O 设备的信号 | 异步 | 总是返回到下一条指令 | 定时器展示信号、I/O 完成 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 | 系统调用 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令,也可能不返回 | 缺页 |
| 终止 | 不可恢复的错误 | 同步 | 从不返回 | 除 $0$,一般保护故障 |
系统调用包括 read,write 等 I/O 函数,以及 mmap,getpid,fork,execve,kill 之类的常见的操作。每种系统调用有一个编号,通过在 %rax 中保存该编号,然后用 rdi, rsi, rdx, r10, r8, r9 来传递至多 $6$ 个参数,然后通过汇编指令 syscall 来产生一个陷阱。
一般保护故障包括引用未定义的虚拟内存区域,试图写只读文本段等。
进程
一个进程享有一个独立的虚拟地址空间。不同的进程可以并发地执行。
用户模式和内核模式
摆了。
系统级 I/O
Linux 的哲学是一切皆文件。系统的所有组成部分,包括目录、设备、网络通信等都用文件来刻画。
每一个被程序打开的文件对应一个描述符。初始时打开了三个文件:
- STDIN。
- STDOUT。
- STDERR。
我们讲的顺序可能和原书不一样。
文件元数据
通过如下函数来读取关于文件的信息(称作文件的元数据):
1 | int stat(const char *filename, struct stat *buf); |
其中 stat 结构描述了文件的 inode(唯一标识符,在下面的实验中可以深刻理解到这一点),大小,所有用户,所有用户所在组,创建和修改时间,文件类型和权限(st_mode),还有一些其他的神秘东西。
用下面的 sys/stat.h 中的宏来从 st_mode 里面读取文件类型:
1 | S_ISREG(m) // 这是一个普通文件吗? |
目录也是文件
通过下面的一系列函数可以查询目录信息:
1 | DIR *opendir(const char *name); // 给出目录名,返回一个目录流。 |
其中 dirent 是这样的一个结构:
1 | struct dirent { |
小实验
用下面的代码来获取某个目录下的所有文件:
1 |
|
我的可以发现在 . 下面查到的 . 的 inode 和在 ./attacklab(./ 下面的一个目录)下面查到的 .. 具有相同的 inode。
开关文件
open 函数将 filename 转换为文件描述符,并返回该数字。
1 | int open(char *filename, int flags, mode_t mode); |
其中 flags 是指明访问方式的参数,可以是如下几个东西的或:
O_RDONLY:只读。O_WRONLY:只写。O_RDWR:可读可写。O_CREAT:如果不存在就创建一个空文件。O_TRUNC:如果文件已经存在,就将其截断(理解成清空?)。O_APPEND:每次写之前,将文件位置(可以理解为“光标”)移动到文件结尾。
mode 指明新文件权限,可以是几个掩码的或,每个掩码的结构是前缀接上后缀:其中前缀有 S_IR,S_IW,S_IX 指示读、写、运行权限;后缀包括 USR,GRP,OTH,指示拥有者、拥有者所在组、任何人拥有的权限。
通过 close 关闭一个一打开的描述符。(注意你关闭的是描述符,在已打开文件的组织小节你就会意识到这里的区别)
读写文件
1 | ssize_t read(int fd, void *buf, size_t n); |
read 从描述符 fd 对应的文件里读至多 $n$ 个字节到 buf 里。write 从 buf 开始复制至多 $n$ 个字节到 fd 对应的文件里。返回值为实际上传送的字节数。
注意到遇到下面三种情况,返回值会小于 $n$,此时返回的值称作不足值:
- 读到
EOF。 - 从终端读文件,一行没有 $n$ 这么长。
- 从套接字里读写,发生网络延迟。
据说可以用 lseek 函数来显式修改当前文件的位置,但书上没写怎么用的,摆了。
Robust I/O
自动处理不足值,在对应的描述符里面使劲读写直到读够了或者 EOF。
具体有哪几个函数哥们摆了😄。
关于输入输出函数的选择,有如下经验:
- 尽可能用标准输入输出
scanf/printf。 - 不要用
scanf/rio_readlineb之类的和\n相关的函数来读入二进制文件。 - 对网络套接字用
rio函数。
已打开文件的组织
描述符表指文件表,文件表指 v-node 表。
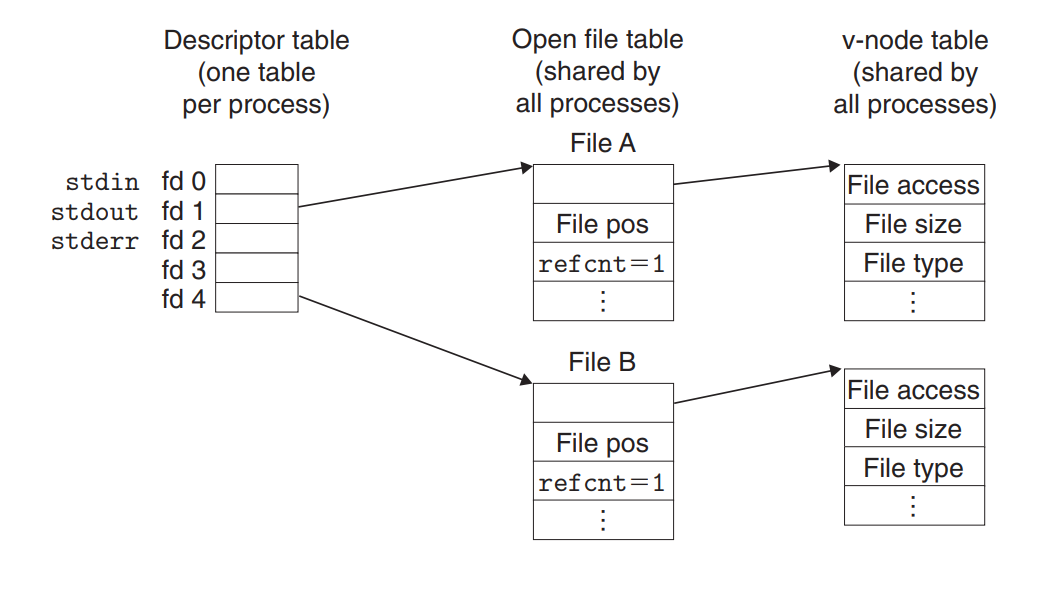
- 描述符表。每个进程有独立的描述符表。表项指向文件表。
- 文件表。所有进程共享,每个表项是一个结构,结构中包含:
- 一个指向 v-node 表的指针。
- 文件位置(“光标”,部分网上资料也管这东西叫做文件偏移量),这个值将在读写文件之后发生变化。
refcnt引用计数。注意这是文件表表项的引用计数,而非对应文件的引用计数。
- v-node 表 包含
stat里面的大部分信息。
当一个文件表表项的 refcnt 为 $0$ 时,其将会被关闭。需要区分下面两种情况:
- 重复打开同名文件:这时候是有两个不同的、
refcnt都是 $1$ 的文件表,指向同一个 v-node 表项。 - 发生
fork创建子进程:子进程会继承父进程的描述符表,但本质是不同的。此时相关文件表的refcnt将加一。
I/O 重定向
在阐释了文件打开的结构之后,I/O 重定向的原理和办法就很显然了:直接改描述符表,骗程序自己在读写原来的文件。
dup2(oldfd, newfd) 将 oldfd 的描述符表表项改成 newfd 的描述符表表项。这样会让 newfd 指向的文件表表项的 refcnt 加一,oldfd 指向的文件表表项的 refcnt 减一。
你可能还会希望重定向回去,这就需要备份原来的描述符表。但是描述符表是内核数据结构。这时候的办法是
1 | int fd_save = dup(fd); // 这样保存原来的描述符表表项 |
并发编程
基于进程的并发编程
每次 accept 完就 fork 一个子进程。注意父进程需要关闭已连接的描述符 connfd,子进程需要关闭监听套接字 listenfd,结束后要关闭 connfd,否则会一直占用系统资源。
需要一个 SIGCHLD 的处理程序(while(waitpid(-1, 0, WNOHANG)); 状物)。
Remark. 这里父进程关闭
confd之后,对connfd的文件表影响只是refcnt减一,子进程仍然可以用confd读写。子进程也可以不关闭
connfd,因为进程因为某种原因终止时,内核会自动关闭它打开的文件。
进程之间有独立的地址空间,可以避免很多并发错误,但是为了共享信息必须使用显式 IPC 机制,而且上下文切换非常慢。
基于 I/O 多路复用的并发编程
select 函数
主要依赖 select 函数及其配套操作。select 函数非常复杂,我们将后面三个参数都设置为 NULL 来使用其功能之一:挂起进程,知道一组描述符准备好读。
首先引入类型 fd_set 类型抽象了一个描述符的集合,提供了若干个访问此集合的接口:
1 | FD_ZERO(fd_set *fd_et); // 清空集合 |
接下来介绍 select 函数的原型(n 是 fdset 的最大值加一):
1 | int select(int n, fd_set* fdset, NULL, NULL, NULL); |
本函数将挂起当前进程,直到 fdset 中的某些描述符准备好读了。此函数返回已准备好的描述符个数(非零),若出错返回 $-1$,同时有个副作用是将 fdset 重置为准备好读的子集。
现在如果你将 STDIN_FILNO 和 listen_fd 添加到 fdset 当中,然后 select(listen_fd + 1, fdset),就可以同时接受来自标准输入和连接的读入,从而实现了等效意义上的并发。
并发事件驱动服务器
你可能希望事件的粒度更细,比如说从一个 connfd 中读入一行就响应一次乃至读入一个字符就响应一次之类的。
这时容易想象的办法是手动把处理事件的逻辑流建模成一个状态机(回忆一个状态机就是一个带副作用的 DFA)。比如如果只是读一行,那么状态机上只有一个状态,代表“等待描述符 connfd 准备好读”,转移只有一个自环,这个自环是事件“connfd 准备好读了”,副作用是从 connfd 中读一行并且做一些操作。
代码非常唐而且长,摆了。
优点
- 将所有东西集中在一个代码中,所以你对各个连接的控制能力非常强,可以提供针对性的服务。
- 逻辑流之间的通信很容易。
- 单进程程序方便调试。
- 没有上下文切换的时间开销。
缺点
- 编码复杂。你需要把一段代码手动搓成状态机。
- 一攻击整个服务器直接寄完。
基于线程的并发编程
线程系指运行在进程上下文中的逻辑流。一个进程中的所有线程共享该进程的整个虚拟地址空间、具有相同的地位(主线程和对等线程的区别只是它是第一个运行的线程)
共享内存模型
书的顺序有点令人迷惑,我们先讲理论,然后在讲一些函数。
每个线程拥有自己独立的线程上下文,包括线程 ID、栈、栈指针、程序计数器、条件码、通用目的寄存器值。每个线程和其他线程共享进程上下文的其他部分。
这里说的独立栈可能让人难以理解,我们做了一些测试,发现它实际上就是在虚拟地址空间中的栈区域里给每个线程分配了一段小栈:
测试内容
运行代码:
1 |
|
得到如下结果:
1 | Main thread: 7fff2b60a578 |
这个小栈是不对其他线程设防的。
基于以上线程上下文的模型,我们可以知道在多线程编程时:
- 全局变量 在虚拟内存中只有一份,是共享的。
- 本地静态变量 在虚拟内存中只有一份,是共享的。
- 局部变量 在每个线程的栈上都有一份,基本上是私有的。(说基本上是因为栈不设防)
Posix 线程
关于线程的一套接口。方便起见我们定义如下线程例程的类型:
1 | typedef void *(func)(void *); // 将 func 定义为 void* -> void* 的函数 |
函数的参数和返回值都是通用指针,应该是用来实现多态的。
通过 pthread_create 来创建线程:
1 | int pthread_create(pthread_t *tid, pthread_attr_t *attr, func *f, void *arg); |
此函数创建一个新线程,在新线程中运行函数(称作线程例程) f(向 f 传入参数 *arg)。attr 是一些关于新线程默认属性的参数,这里不讲。新线程的 id 通过被存到 *tid 里面来告知主线程。
通过 pthread_self 来获得自己的线程 ID。
1 | pthread_t pthread_self(void); |
线程终止可能是如下几种情况:
线程例程返回。
调用
pthread_exit显示终止线程。1
void pthread_exit(void *thread_return);
参数是线程的返回值。主线程调用此函数后会等待其他对等线程终止,然后主线程和整个进程才终止。
对等线程调用
exit(),那么整个进程全部终止。调用
pthread_cancel()来杀掉对等线程。1
void pthread_cancel(pthread_t tid);
通过 pthread_join 来等待其他线程终止,获取其返回值(注意和 wait 不一样,你只能指定等待某一个线程终止),并回收其资源:
1 | int pthread_join(pthread_t tid, void **thread_return); |
通过 pthread_detach 来分离线程。线程是可结合的或者分离的。一个可结合的线程在被其他线程回收之前,其资源(如栈)都是不释放的。一个分离的线程不能被其他线程回收或者杀死,其终止时系统自动回收资源。默认情况下线程都是可结合的。
1 | int pthread_detach(pthread_t tid); |
通过 pthread_once 来做初始化。
1 | pthread_once_t once_control = PTHREAD_ONCE_INIT; |
once_control 是一个指示初始化函数分类的标记:pthread_once 函数的作用是在第一次以 once_control 为参数调用的时候,其调用 init_routine,此后再一次以 once_control 为参数调用,它不做任何事情。
可以想象这玩意是用来在多线程编程时初始化一些共享全局变量的。
基于线程的并发服务器
每次 accept 到一个连接,就 pthread_create 一个对等线程。现在核心的问题是怎么把 connfd 传递给对等线程。
直觉上办法是直接用 &connfd 传。但回忆主线程和对等线程运行的顺序是不确定,所以如果对等线程做 int connfd = *((int *)vargp) 之前,主线程又收到了一个连接然后改变了 connfd 就倒闭了。
正确的办法是主线程 malloc 一个空间,然后把 connfd 存进去。对等线程拿到 connfd 之后 free 掉这个空间(vargp)来防止内存泄漏。
线程同步和资源调度
因为线程中存在一些共享变量,所以会有一些阴间问题。
竞争
一个例子是,假设 cnt 是一个全局变量,那么在做 cnt++ 时,其实汇编是有三个阶段的:从加载,运算,写回。如果两个线程的执行顺序为:
- 线程 1 访存,线程 2 访存。
- 线程 1 运算,线程 2 运算,线程 1 写回,线程 2 写回。
那么实际上 cnt 只被加了一次。直观地,可以画出如下的进度图(在这个局部意义下,一个线程分为 $H$ 头、$L$ 加载,$U$ 运算,$S$ 写回,$T$ 尾五部分,图上的坐标点 $(x, y)$ 表示线程 1 在 $x$ 阶段,线程 2 在 $y$ 阶段)
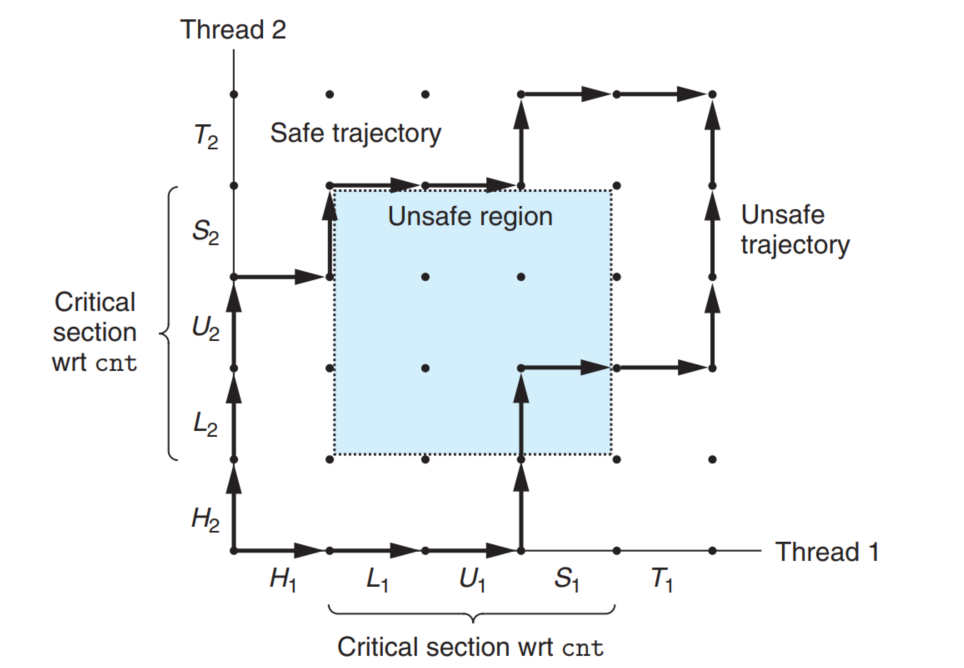
这样的不安全是操作非原子导致的。可以通过信号量来规避这种情况。
1 | int sem_init(sem_t *sem, 0, unsigned int value); // 将信号量 sem 初始化为 value |
$P(s)$ 和 $V(s)$ 是 Dijkstra 提出的两种抽象的原子操作。
- $P(s)$:如果 $s$ 非零,那么将 $s$ 减一,并立即返回。否则,挂起该线程,直到 $s$ 变成非零。在重启时才执行前面的操作。
- $V(s)$:将 $s$ 加一,并重启某一个阻塞在 $P(s)$ 上的线程。
所以如果你在 cnt++ 前面 $P$ 一下,后面 $V$ 一下,就不可能出现上面的情况。几何上相当于用一个禁止区完全包住了不安全区。
另一个例子是上一节讲的传入 connfd 的例子。
死锁
可以想象如果你有两组锁,两个线程分别是:
1 | // thread 1 |
如果运行顺序让线程 $1$ 先持有 $s$,线程 $2$ 持有 $t$,那么他们就会卡在第二行,出现死锁。直观地:
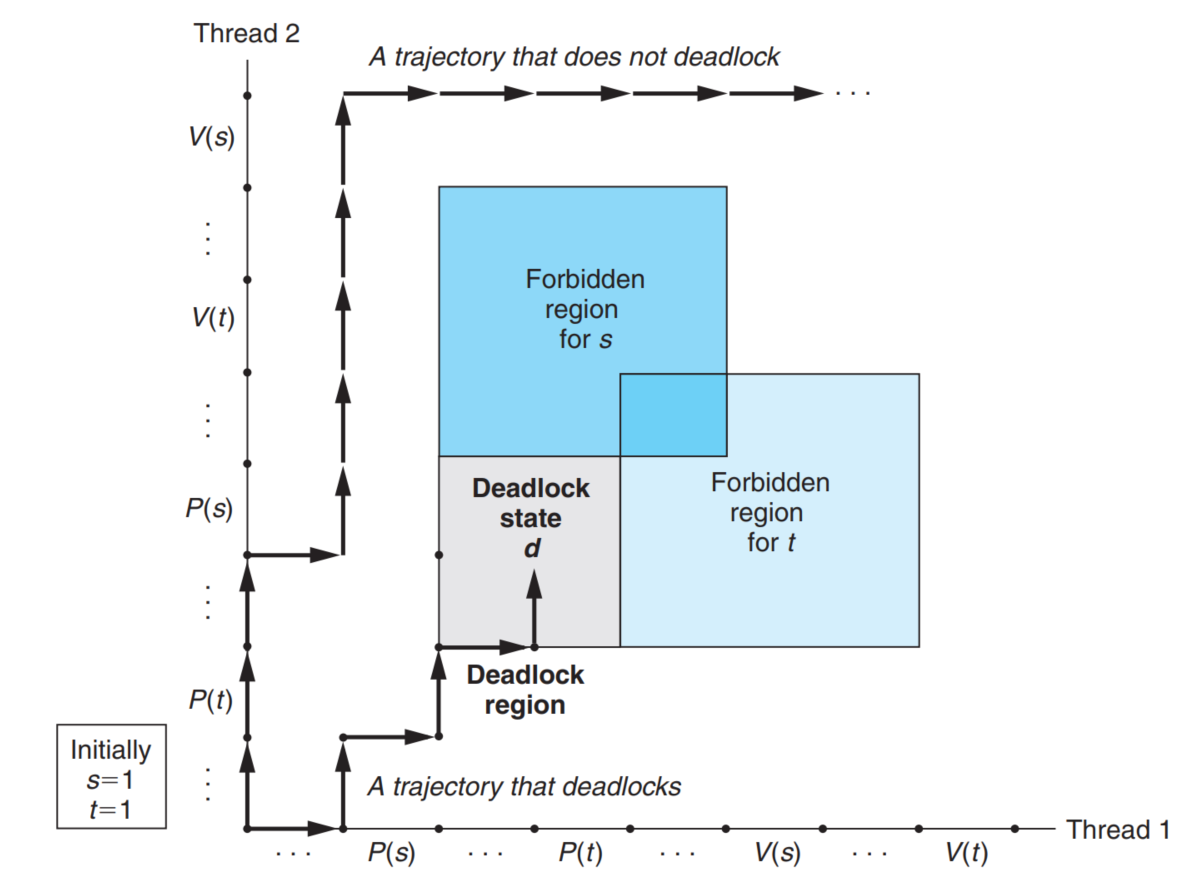
但是有如下结论:
定理. 如果为所有信号量指定一个全序,所有线程均按照该全序从小到大加锁,并按照相反的顺序释放,那么一定不会有死锁。
证明.
假设有 $n$ 个信号量,考虑在线程 $i$ 做 $P(s_i)$ 的时候出现了死锁。定义集合 $S = \{s_1, …, s_n\}$,$S$ 是有限全序集的子集,其中有极大元。
但是根据死锁的定义,对于任意 $s_i$,都存在一个 $j$ 使得线程 $j$ 中 $P$ 了 $s_i$。因为我们按照全序从小到大加锁,所以 $s_j > s_i$。$s_i$ 都不是极大元。这导出了矛盾。$\square$
线程安全
主要有以下四类线程不安全的函数:
- 不保护共享变量。修改方法是加锁。
- 保持跨越多个调用的状态的函数。比如
rand(),你可能希望指定seed之后每个线程都生成一样的序列,但是seed是一个静态变量,就不能达到这个效果。修改方法是重写。 - 返回指向静态变量得到指针的函数。这样会导致竞争。除了重写之外,可以使用加锁-复制技术:在调用该函数时加锁,然后把结果拷贝到私有地址上,然后释放。这种技术有一些缺点,比如加锁降低效率、如果返回了一个链表之类的东西你需要深复制整个链表。
- 调用线程不安全的函数。如果调用第二类不安全函数,那么就没什么救。否则可以调用前加锁,加锁之后就还是线程安全的。
可重入函数是线程安全的。其定义是在被任意多个线程调用时都不会有共享变量。可以进一步分成两类:
- 显式可重入:通过值传参,而且只有局部变量。
- 隐式可重入:传参可以用指针。此时如果你传参足够小心,就确实还是可重入。
大部分 Linux 函数都是线程安全的,包括 malloc,free,realloc,printf,scanf 等。
rand 和 strtok(不知道是干什么的)属于第二类线程不安全函数。其他还有一些 ctime,asctime,localtime 和一堆 gethostbyname,gethostbyaddr,inet_ntoa 之类的网络编程函数是第三类线程不安全函数。
接下来讲两类资源调度问题。
生产者-消费者问题
生产者线程往一个缓冲区里面写东西,消费者线程从缓冲区拿东西出来处理。有如下限制:
- 不能并发读写。
- 缓冲区满时生产者不能写。
- 缓冲区空时消费者不能读。
思路是在信号量里面存空闲块的数量和待处理块的数量。(sbuf_init 是一个带有三个信号量的循环队列,这里我们只考察信号量)
1 | void sbuf_init(sbuf_t *sp, int n) { |
在服务器问题中可以抽象出一个生产者-消费者问题。每次 accept 一个新的 connfd 就往缓冲区写一个 connfd。然后一些线程作为消费者来处理这些 connfd。这样的优化叫做预线程化,优化了每次连接时开新线程的时间。
读者-写者问题
这是对 CREW 问题的一种抽象。要求
- 读者可以同时读。
- 写者在写时必须控制整个缓冲区。
有两种变种,一类是读者优先(除非写者正在写,不能让读者等待),一类是写者优先。我们讨论读者优先,写者优先是对称的。
只需要维护正在读的读者数量 readcnt 和刻画写者权限的信号量 w。一旦 readcnt > 0,就 $P(w)$。
1 | void reader() { |