Revision | 计算机系统小常识(上)
Abstract. ICS 期中复习笔记。主要涉及机器级编程,流水线处理器设计,高层次的程序优化,存储器层次结构等。参考资料是Randal E Bryant, David R. O’Hallaron,深入理解计算机系统(第三版),机械工业出版社(2016) 的三到六章。关于数据类型的章节是平凡的,因此跳过。
机器级编程
寄存器
| 四字 | 双字 | 字 | 字节 |
|---|---|---|---|
| %rax | %eax | %ax | %al |
| %rbx | %ebx | %bx | %bl |
| %rcx | %ecx | %cx | %cl |
| %rdx | %edx | %dx | %dl |
| %rsi | %esi | %si | %sil |
| %rdi | %edi | %di | %dil |
| %rbp | %ebp | %bp | %bpl |
| %rsp | %esp | %sp | %spl |
| %r8 - %r15 | %r8d - %r15d | %r8w - %r15w | %r8b - %r15b |
- %rbx, %rbp, %r12 - %r15 是被调用者保存寄存器,其余除了 %rsp 外是调用者保存寄存器。
- 对于寄存器的修改:对于生成 1、2 字节数字的指令,保持剩下的字节不变。生成 4 字节的指令会将高位置为零。
数据传送指令:
常规的
movq只能以 32 位补码的立即数作为源;movabsq能传送任意 64 位立即数,只能以寄存器作为目标。movzxx用于将数据做零扩展之后传送到目标,但是没有movltq指令,参见寄存器部分的第 2 条。movsxx将数据符号扩展后传送,特别地cltq将 %eax 符号扩展到 %rax。其效果等同于 movslq %eax, %rax,但是编码更短。条件传送只能使用 16 位,32 位,64 位的源和目的值。只能传到寄存器,汇编器会根据参数分析长度。
和指针有关的语句采用条件传送时要格外注意内存错误,比方说如下代码
1
2
3long cread(long *xp) {
return xp? (*xp : 0);
}并不能翻译成
1
2
3
4
5
6cread:
movq (%rdi), %rax
testq %rdi, %rdi
movl $0, %rdx
cmove %rdi, %rax
ret因为这样传入 NULL 第 2 行会访问 0 地址而出错。
算术和逻辑操作
leaq不设置条件码。有
INC,DEC指令用于加减 1,NEG用于取负。有如下几个特殊指令提供给 128 位整数操作:
指令 效果 描述 imulq SR[%rdx] : R[%rax] = S * R[%rax] 有符号全乘法 mulqR[%rdx] : R[%rax] = S * R[%rax] 无符号全乘法 cqtoR[%rdx] : R[%rax] = R[%rax] 符号扩展 %rax idivqR[%rdx] = R[%rdx] : R[%rax] mod S
R[%rax] = R[%rdx] : R[%rax] / S有符号除法 divqR[%rdx] = R[%rdx] : R[%rax] mod S
R[%rax] = R[%rdx] : R[%rax] / S无符号出发 表 1.2:特殊算术操作表
条件码
注意 cmp 相当于无目标的 sub,test 相当于无目标的 and。下面默写跳转条件和条件码之间的对应关系:
| 指令 | 同义名 | 条件码 | 解释(操作数 vs. 被操作数) |
|---|---|---|---|
| e | z | ·ZF |
相等 / 零 |
| ne | nz | ~ZF |
不等 / 非零 |
| s | SF |
负 | |
| ns | ~SF |
非负 | |
| g | nle | ~(SF^OF) & ~ZF |
大于 |
| ge | nl | ~(SF^OF) |
大于等于 |
| l | nge | SF^OF |
小于 |
| le | ng | (SF^OF) | ~ZF |
小于等于 |
| a | nbe | ~CF & ~ZF |
无符号大于 |
| ae | nb | ~CF |
无符号大于等于 |
| b | nae | CF |
无符号小于 |
| be | na | CF | ZF |
无符号小于等于 |
- 移位操作会将最后一个移出的位放在 CF,不改变 OF。
Update. 这句话是书上写的,实际上是错的。实际上查阅 intel 的 x86-64 手册可以知道当仅移动一位时会将 OF 设置为最高位异或新的最高位。
inc,dec会改变 SF、OF,不改变 CF。set指令用于根据条件码给一个字节赋值。
运行时栈
每个栈帧从下到上(注意栈顶是低地址)依次是保存寄存器、局部变量、参数(编号从顶往下递增)。
call指令除了直接跳转之外,还可以call *Operand以间接寻址(其中 Operand 是Imm(Ra, Ri, s)格式)。每种数据类型必须对齐到其大小的倍数。
若使用了 SSE 指令,栈帧边界必须是 16 的倍数。
用 %rbp(帧指针)来处理变长栈帧(函数中开变长数组)。
leave指令相当于1
2movq %rbp, %rsp
popq %rbp # %rbp 是调用者保存,理应被备份在上方。
指针类型解读
从名称开始,优先结合括号,然后结合解引用。比如说 int *f(int *); 声明的是一个函数,传入一个 int* 返回一个 int*。int (*f)(int*) 才是指向输入 int* 返回 int 的函数的指针。
*浮点代码
讨论基于 AVX 指令集,且只讨论基础的部分。
寄存器名为 %ymm0 - %ymm15,均为256 位寄存器(称为 YMM 寄存器),其低 128 位(称为 XMM 寄存器)名称为 %xmm。%ymm0 为返回值,%ymm0 - %ymm7 用于传参,所有 XMM 寄存器均为调用者保存。
寄存器中保存的值可以视为标量或者矢量。在标量操作中,只会使用 %xmm 寄存器的低 64 / 32 位。
传送指令
vmov系指令指令 描述 vmovss在 XMM 寄存器和内存间传送单精度浮点数标量 vmovsd在 XMM 寄存器和内存间传送双精度浮点数标量 vmovaps在 XMM 寄存器之间传送单精度浮点数 vmovapd在 XMM 寄存器之间传送双精度浮点数 注意
vmovaps/d中的a表示对齐,若操作数地址不是对 16 位对其会出现异常。但是在寄存器之间的操作不存在不对齐。转换指令
vcvt系指令在后面加上:
t(Truncation,截断的缩写),ss单精度浮点数 /sd双精度浮点数,2(to 的简称),si有符号整数 /siq有符号长整数得到将浮点数截断、向零舍入后转成整形的指令。其源操作数为 XMM 寄存器或内存,目标为寄存器。如vcvttss2siq表示将单精度浮点数截断后转成long long。在后面加上
si,2,ss/sd,q?(是否为长整数)得到将整数转换为浮点数的结果。其源操作数有两个,第一个为内存或寄存器,第二个为 XMM 寄存器(此源不影响低位,可以忽略),目标为 XMM 寄存器。vcvtss2sd将单精度转为双精度,但不知为何 GCC 生成如下代码(回忆 %xmm 寄存器保存的值可以看作包装好的矢量):1
2vunpck1ps %xmm0, %xmm0, %xmm0 # [s3, s2, s1, s0], [d3, d2, d1, d0] -> [s1, d1, s0, d0]
vcvtps2pd %xmm0, %xmm0 # [*, *, s1, s0] -> [double(s1), double(s0)]vcvtsd2ss将双精度转为单精度,但不知为何 GCC 生成如下代码1
2vmovddup %xmm0, %xmm0 # [*, x0] -> [x0, x0]
vcvtpd2psx %xmm0, %xmm0 # [x1, x0] -> [0, 0, x1, x0]运算指令 算术运算包含
vadd,vsub,vmul,vdiv,vmax,vmin,sqrt(后接ss/sd指明精度),对于二元运算,第一个操作数可以是 XMM 寄存器或者内存,第二个操作数必须是 XMM 寄存器。逻辑运算包含vxor, vand(后接ps/pd指明精度)。此外vucomi(后接ss/sd指明精度)用于比较浮点数,其作用类似于cmp。条件码包含ZF, CF以及PF(奇偶标志位,在整数操作中标记最低字节中 $1$ 个数是否为偶数,不常用),规则如下(vucomiss S1, S2,基于 $S_2 - S_1$):序关系 ZF CF PF 无序 1 1 1 $S_2< S_1$ 0 1 0 $S_2 = S_1$ 1 0 0 $S_2 > S_1$ 0 0 0 由于比大小时
ZF,CF的行为类似于无符号整数操作,跳转使用ja,jb。判断无序(存在 NaN)jp等。浮点常量必须事先定义并存储在 Text 区。比如
1
2
3.LC2:
.long 0xcccccccd
.long 0x3ffccccc.long是汇编伪指令,指明一个四比特的值,上述值给出了 double 类型的 $1.8$。
处理器体系结构
在下文的图片中,灰底圆角框表示组合电路,白底圆框表示线路名,蓝底方框表示特殊电路,白底方框表示寄存器。虚线表示一位,细线表示四位数据,粗线表示八字节数据。
SEQ
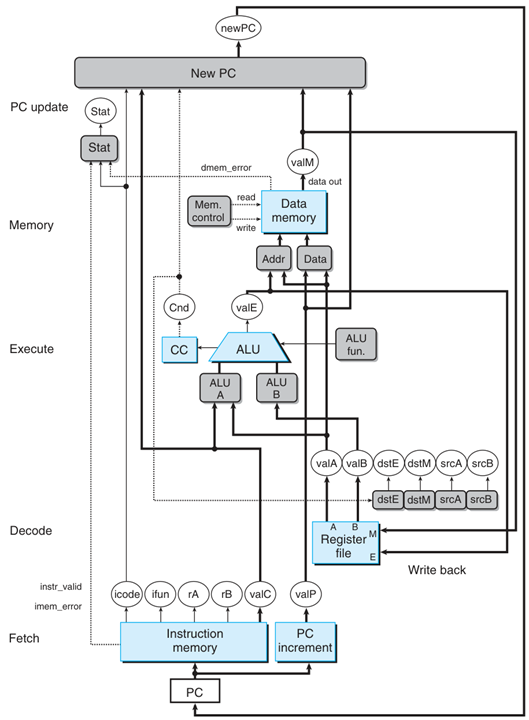
线路概览:
- 取指 icode,ifun,rA,rB,valC,valP
- 译码 valA,valB
- 执行 valE
- 访存 valM
- 写回
- 更新 PC
指令运行跟踪:
| 阶段 | cmovXX rA, rB | irmovq V, rB | rmmovq rA, D(rB) | mrmovq D(rB), rA |
|---|---|---|---|---|
| 取指 | icode : ifun = $M_1[PC]$ rA : rB = $M_1[PC + 1]$ valP = PC + 2 |
icode : ifun = $M_1[PC]$ rA : rB = $M_1[PC + 1]$ valC = $M_8[PC + 2]$ valP = PC + 10 |
icode : ifun = $M_1[PC]$ rA : rB = $M_1[PC + 1]$ valC = $M_8[PC + 2]$ valP = PC + 10 |
icode : ifun = $M_1[PC]$ rA : rB = $M_1[PC + 1]$ valC = $M_8[PC + 2]$ valP = PC + 10 |
| 译码 | valA = R[rA] | valA = R[rA] valB = R[rB] |
valB = R[rB] | |
| 执行 | valE = valA + 0 Cnd = Cond(CC, ifun) |
valE = valC + 0 | valE = valC + valB | valE = valC + valB |
| 访存 | M[valE] = valA | valM = M[valE] | ||
| 写回 (dst_E) | if(Cnd) R[rB] = valE | R[rB] = valE | ||
| 写回 (dst_M) | R[rA] = valM | |||
| 更新 PC | PC = valP | PC = valP | PC = valP | PC = valP |
| 阶段 | OPq rA, rB | pushq rA | popq rA |
|---|---|---|---|
| 取指 | icode : ifun = $M_1[PC]$ rA : rB = $M_2[PC + 1]$ valP = PC + 2 |
icode : ifun = $M_1[PC]$ rA : rB = $M_2[PC + 1]$ valP = PC + 2 |
icode : ifun = $M_1[PC]$ rA : rB = $M_2[PC + 1]$ valP = PC + 2 |
| 译码 | valA = R[rA] valB = R[rB] |
valA = R[rA] valB = R[%rsp] |
valA = R[%rsp] valB = R[%rsp] |
| 执行 | valE = valA OP valB set CC |
valE = valB - 8 | valE = valB + 8 |
| 访存 | M[valE] = valA | valM = M[valA] | |
| 写回 (dst_E) | R[rB] = valE | R[%rsp] = valE | R[%rsp] = valE |
| 写回 (dst_M) | R[rA] = valM | ||
| 更新 PC | PC = valP | PC = valP | PC = valP |
| 阶段 | jXX Dest | call Dest | ret |
|---|---|---|---|
| 取指 | icode : ifun = $M_1[PC]$ valC = $M_8[PC + 1]$ valP = PC + 9 |
icode : ifun = $M_1[PC]$ valC = $M_8[PC + 1]$ valP = PC + 9 |
icode : ifun = $M_1[PC]$ |
| 译码 | valB = R[%rsp] | valA = R[%rsp] valB = R[%rsp] |
|
| 执行 | Cnd = Cond(CC, ifun) | valE = valB - 8 | valE = valB + 8 |
| 访存 | M[valE] = valP | valM = M[valA] | |
| 写回(dst_E) | R[%rsp] = valE | R[%rsp] = valE | |
| 写回(dst_M) | |||
| 更新 PC | PC = Cnd? valC : valP | PC = valC | PC = valM |
根据上表对一些蓝色格子(无法用 HCL 写出)做解释,并写几个重点灰色格子的 HCL。
取指 Instruction Memory 在读入指令不合法时会通过
imem_error信号传递信号给状态码,并假装去除了 nop。Align 单元根据读入的后 9 字节以及
need_regids信号来将数据装入rA,rB,valC。如果指令不需要寄存器,则rA = rB = F。1
bool need_regids = icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ, IIRMOVQ, IRMMOVQ, IMRMOVQ };
PC Increment 单元根据
need_valC和need_regids信号决定 PC 的增加量(给出valP)。need_valC的 HCL 和上面类似,这里不写。译码、写回 考察
dstE,dstM,srcA,srcB四个信号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20word srcA = [
icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : rA;
icode in { IPOPQ, IRET } : RRSP;
1 : RNONE;
];
word srcB = [
icode in { IOPQ, IRMMOVQ, IMRMOVQ } : rB;
icode ib { IPUSHQ, IPOPQ, IRET, ICALL } : RRSP;
1 : RNONE
];
word dstE = [
icode in { IRRMOVQ } && Cnd : rB;
icode in { IOPQ, IIRMOVQ } : rB;
icode in { IPUSHQ, IPOPQ, IRET, ICALL } : RRSP;
1 : RNONE;
];
word dstM = [
icode in { IMRMOVQ, IPOPQ } : rA;
1 : RNONE;
];注意
popq指令同时使用了dstE和dstM,为了避免冲突我们令写入时dstM的优先级更高,这导致popq %rsp后 rsp 中是内存里的值。同时观察处理器结构可以知道pushq %rsp会将 rsp 原来的值存入。执行 需要考察
SetCC, aluA, aluB, alufun四个信号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15word aluA = [
icode in { IOPQ, IRRMOVQ } : valA;
icode in { IMRMOVQ, IRMMOVQ, IIRMOVQ } : valC;
icode in { ICALL, IPUSHQ } : -8;
icode in { IPOPQ, IRET } : 8;
];
word aluB = [
icode in { IRRMOVQ, IIRMOVQ } : 0;
icode in { IOPQ, ICALL, IPUSHQ, IPOPQ, IRET, IMRMOVQ, IRMMOVQ } : rB;
];
word SetCC = icode in { IOPQ };
word alufun = [
icode == IOPQ : ifun;
1 : ALUADD;
];访存 需要考察
mem_addr, mem_data, mem_read, mem_write四个信号1
2
3
4
5
6
7
8
9
10word mem_addr = [
icode in { IRMMOVQ, IMRMOVQ, IPUSHQ, ICALL } : valE;
icode in { IPOPQ, IRET } : valA;
];
word mem_data = [
icode in { IRMMOVQ, IPUSHQ } : valA;
icode in { ICALL } : valP;
];
word mem_read = icode in { IMRMOVQ, IPOPQ, IRET };
word mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL };此时如果访存地址错误,Data Memory 会给出信号
dmem_error,结合此前的imem_error和instr_valid,可以更新状态码,考察信号State:1
2
3
4
5
6word Stat = [
imem_error || dmem_error : SADR;
!instr_valid : SINS;
icode = IHALT : SHALT;
1 : SAOK;
];更新 PC 考察信号
new_pc1
2
3
4
5
6word new_pc = [
icode == ICALL : valC;
icode == IJXX && Cnd : valC;
icode == IRET : valM;
1 : valP;
];
SEQ+
对电路进行重定时,将 PC 计算从周期末尾移动到周期开头:引入寄存器 pIcode, pCnd, pValM, pValC, pValP。然后将 new_pc 改为组合电路,直接输出 PC。
PIPE-
插入流水线寄存器。每周期通过 Select PC 信号预测下一周期执行的指令,每周期发射一条。
现在每一个信号前面需要加上阶段性标识。直接从流水线寄存器中取出的信号前面加对应的大写字母,经过计算之后的前面加对应的小写字母。
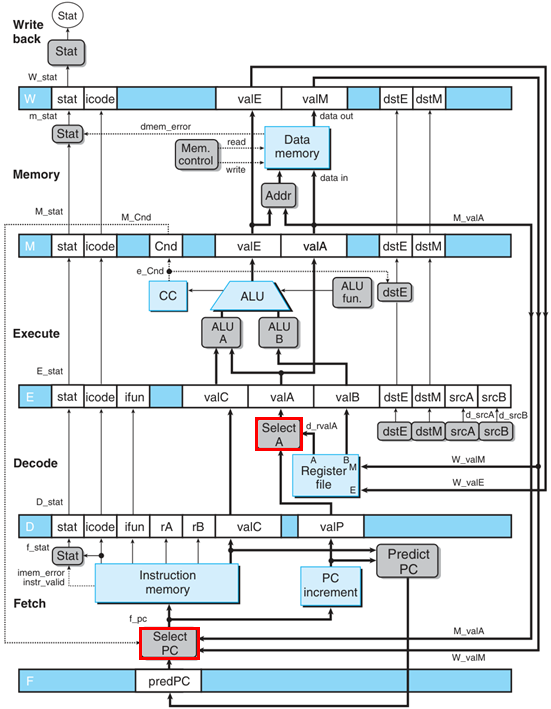
注意一些细节:
valP产生后共有两种去向:用于决定下一个 PC,和写入内存(仅call指令),然而大部分情况下决定下一个 PC 就在F阶段,除开IJXX指令要拖到执行阶段完成后才知道,但IJXX也不会使用valA;写入内存时不会使用valA,因此后面的周期都没有valP寄存器,只有valA寄存器。srcA和srcB看似没有输出口(即使到了 PIPE 的设计图中也不会有输出口),这是一个伏笔,留下这两个寄存器是为了进行加载转发以避免加载使用冒险。- 这个流水线设计有问题,因为没有控制逻辑,对流水线冒险无能为力。
分支预测策略
除开控制系指令外的指令,显然直接预测 valP。对于其他指令:
jXX指令,我们选择总是跳转(预测valC)。call指令,自然预测valC。ret指令,不做任何预测,直接暂停处理指令。
我们预先说明一下流水线寄存器模块的模式,通过两个单位信号 Stall 和 Bubble 来控制:
- Normal,正常输入输出。
- Stalling,锁存。
- Bubble,在时钟上升沿将寄存值置为
nop状。
若 Stall 和 Bubble 同时是 1 会发生错误。
PIPE
加入控制逻辑(未画出)和转发线
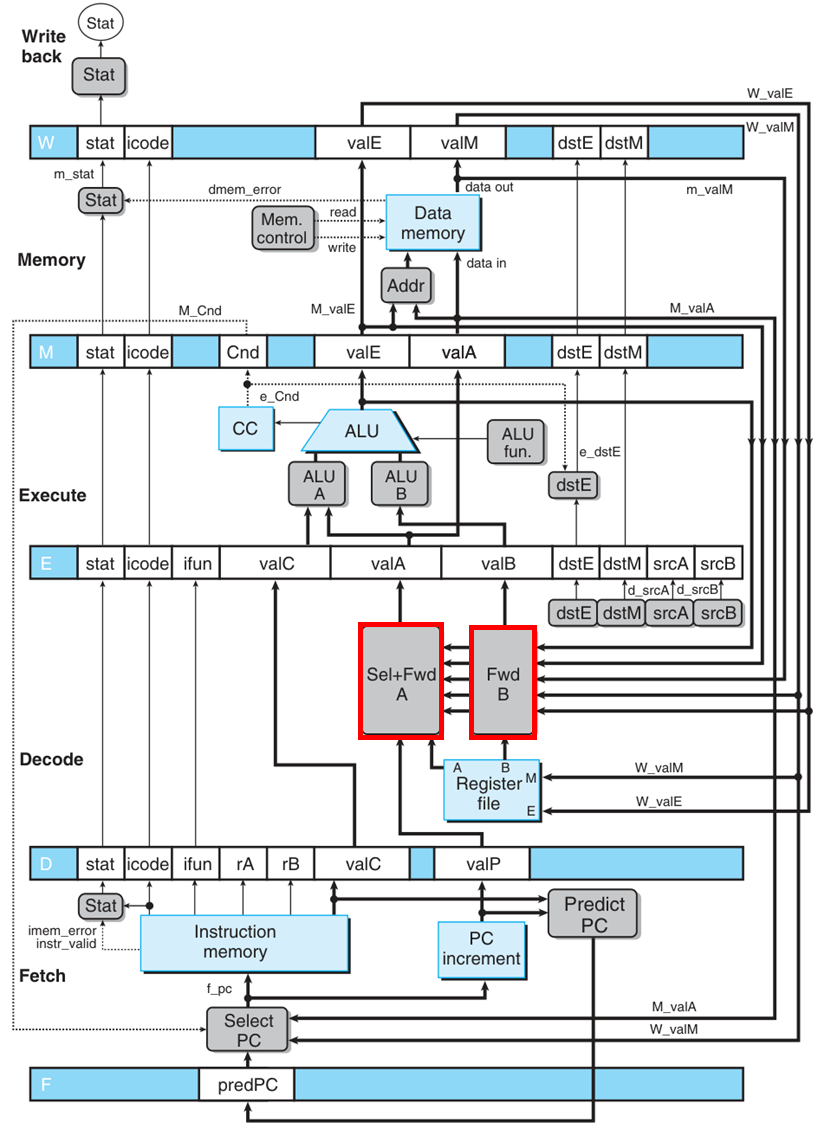
我们将分阶段写 HCL。只有取指和译码阶段会有额外的电路要写(其余都只是在原来的信号前面加标识流水线阶段的前缀),此外还有一套控制逻辑要写。
取指阶段 有 icode,ifun,instr_valid,needregids,needvalC 等指令,是平凡的,着重考虑 f_pc(由组合电路 Select PC 给出), f_predPC(由组合电路 Predict PC 给出)和 f_stat(由 Stat 给出)三个信号。
1 | word f_pc = [ |
译码阶段
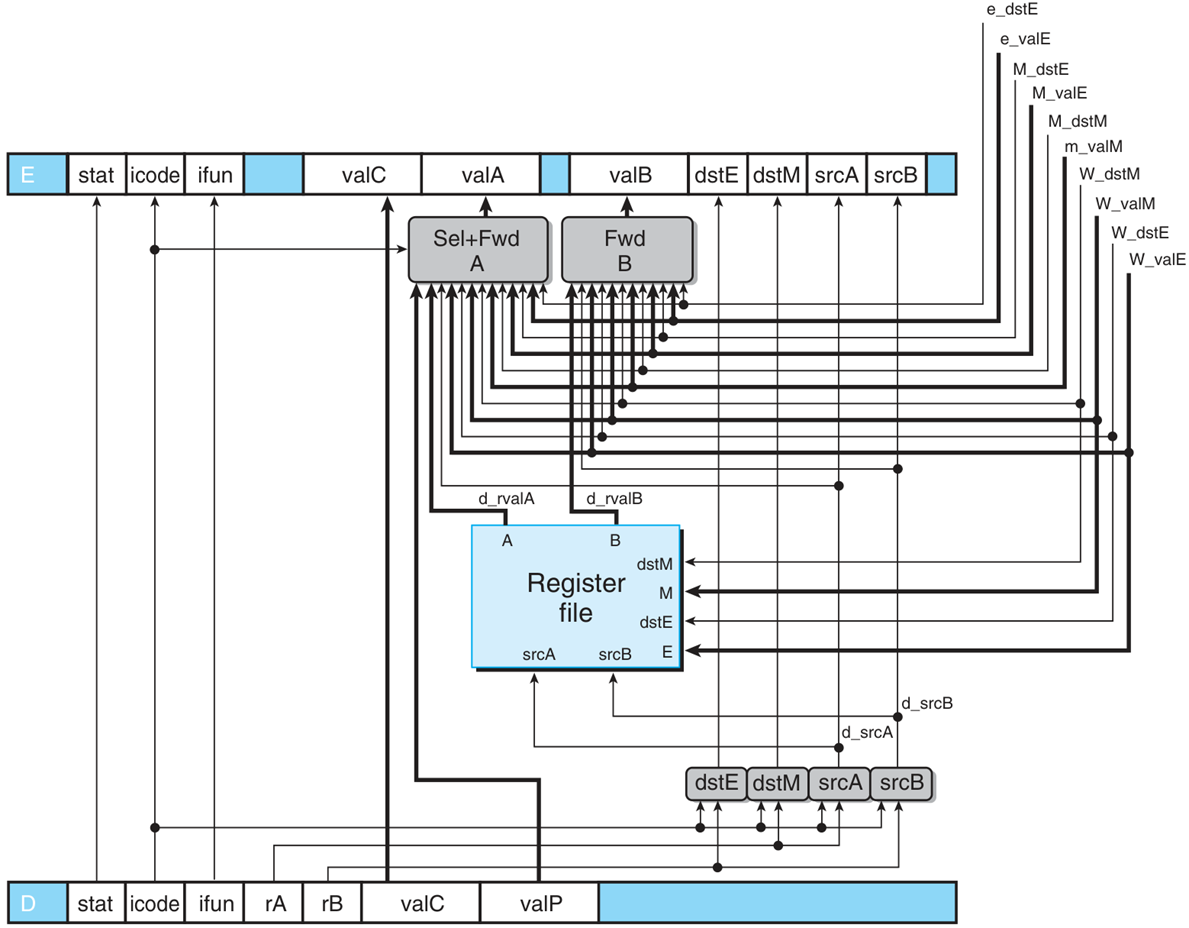
下方四个信号仅仅是在 SEQ 的基础上加上前缀 D_ 和 d_。着重考察 d_valA 和 d_valB。
1 | word d_valA = [ |
注意代码前后顺序不能交换,因为最后寄存器中的值必然是流水线中最浅的,其次 valE 和 valM 之间存在优先级。
注意 valE 是从 e_dstE 转发来的,因为存在条件转发。
控制逻辑
收集控制的条件:
- 当有一条
ret指令在通过流水线,需要将下一条指令 stall 在F阶段。 - 当发生加载 / 使用冒险(运算的操作数需要从上一条指令内存中取出),必须将运算操作 Stall 一轮。我们会将前后两条指令分别传到执行和译码阶段时处理这件事情。
- 当分支预测错误,必须 Bubble 掉已经执行的错误指令。
- 当发生异常,必须 Stall 住写回阶段,持续 Bubble 访存阶段。
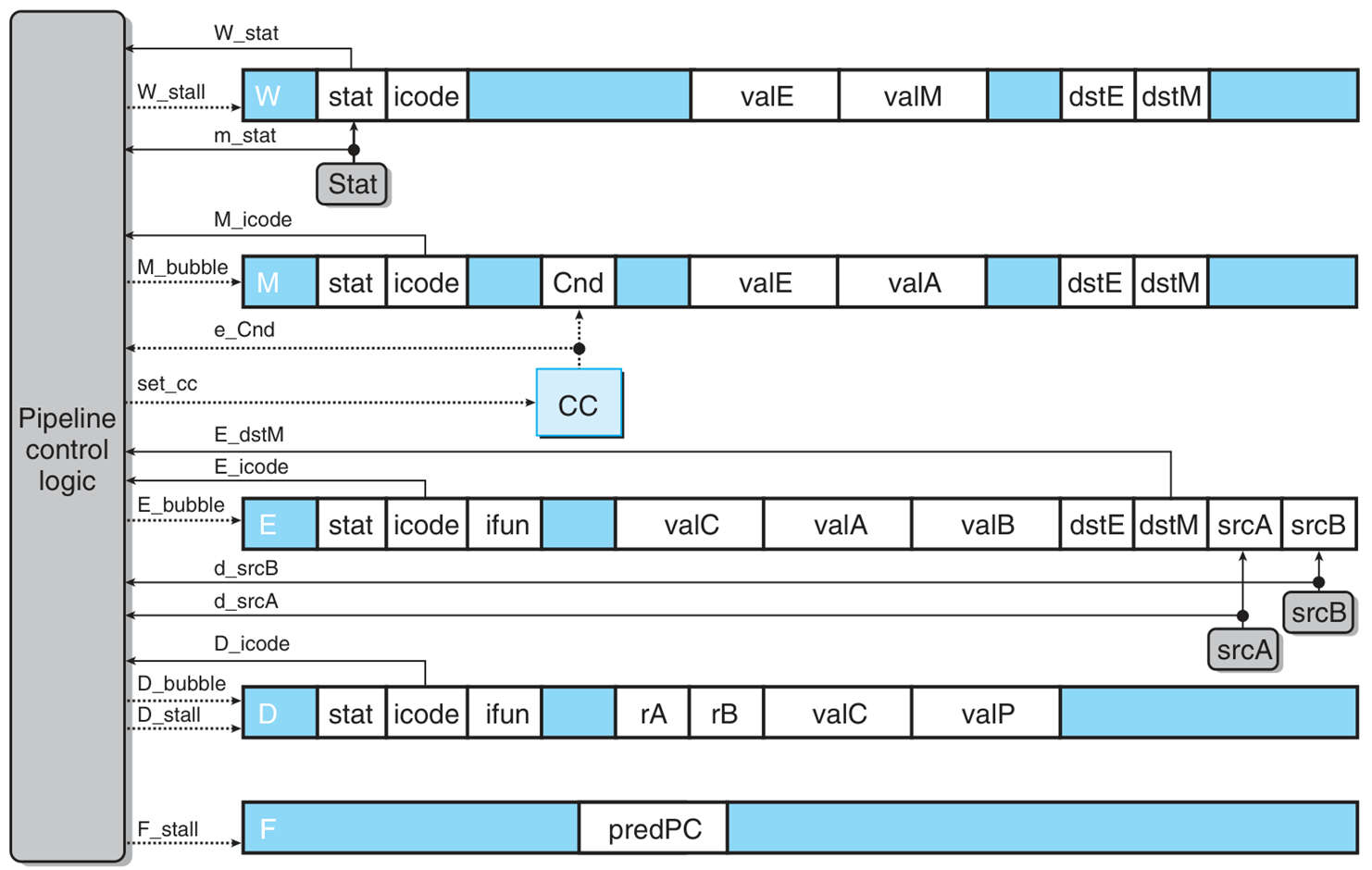
因此从下往上写:
1 | bool F_stall = E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB } || IRET in { D_icode, E_icode, M_icode }; |
有以下注意点:
- 状态在下一个时钟上升沿开始生效。因此在
ret指令在流水线上运行时需要考虑当前阶段是不是ret。 - 译码阶段不能同时 Stall(以处理加载使用冒险)和 Bubble(以处理
ret),Stall 的优先级更高。(但这里真的会寄吗??) - 在执行阶段可以知道分支预测是否错误,下一个周期错误预测的指令将依次传到执行、译码阶段。
实际上对于加载使用冒险,可以从访存阶段转发到执行阶段,但这里需要知道执行阶段的 srcA 和 srcB,这回收了之前的伏笔。
我们没有处理多周期指令(复杂运算 / cache miss 等)。
优化程序性能
比较平凡的优化
编译器优化
只对代码进行安全的优化。有两类不会优化的情况:
内存别名使用
1
2
3
4void twiddle1(long *xp, long *yp) {
*xp += *yp;
*xp += *yp;
}不会被优化成
1
2
3void twiddle2(long *xp, long *yp) {
*xp += 2 * *yp;
}因为必须考虑
*xp = *yp的情况,即便你可以论证这种情况不会出现,编译器也无法推出。函数副作用
1
2
3long func1() {
return f() + f() + f() + f();
}不会被优化成
1
2
3long func2() {
return 4 * f();
}因为
f可能有副作用,调用次数直接影响程序行为。编译器不会尝试判断函数是否有副作用。但是如果给
f加上inline标签,就会直接把代码中的f替换成函数内部的代码,这时即便f有副作用,也可以尝试进一步优化。
程序性能表示
引入每元素的周期数(Cycles Per Element,CPE)。对于一个计算,其处理 $n$ 个元素,我们将得到其运行的总周期数是关于 $n$ 的线性函数 $kn + b$,这里 $k$ 就称为该计算的 CPE。CPE 可以在参考机上完成测量。
消除循环的低效率
对于循环中需要执行多次但是结果不变的数,可以在进循环之前计算,这样可以明显提高 CPE。特别地如果这种数的计算是类似于 strlen 的线性函数,若不提前计算复杂度会变大。
减少过程调用
过程调用会带来额外开销并且妨碍程序优化,因此在写程序时应当尽量不用过程调用。
删除不必要内存引用
考虑如下函数
1 | void combine(int *v, int len, int *dest) { |
这个代码需要两次读内存一次写内存。可以改成
1 | void combine(int *v, int len, int *dest) { |
只需要一次读,acc 可以装在寄存器中。注意编译器不会尝试做此类优化,因为它会假设存在内存别名使用,比如 combine(a, 3, a + 2),但是你知道你不会这样写。
前面写的都是宝宝巴士,下面开始上强度。
相关理论
现代处理器采用所谓的超标量(superscalar)设计,分为指令控制单元(ICU)和执行单元(EU)。ICU 从 icache 中取若干条指令,做分支预测,然后投机执行。EU 中有一组功能单元以在一个时钟周期内接受多个操作。比如 Intel Core i7 Haswell 处理器有 8 个功能单元:
- 整数运算,浮点乘,整数和浮点数除,分支
- 整数运算,浮点加,整数乘,浮点乘
- 加载、地址计算
- 加载、地址计算
- 存储
- 整数运算
- 整数运算、分支
- 存储、地址计算
退役单元用于判断分支预测是否正确。若正确则该指令退役,其更新将被实际执行;否则将被清空,运算结果将被丢弃。
功能单元同样是流水线化的,因此用延迟和吞吐量来描述其性能。延迟系指相互有依赖的指令依次完成的最小 CPE,吞吐量系指 CPE 的下界。将完整运算过程中的依赖关系做成 DAG,其中的最长链称为关键路径(critical path),关键路径的长度决定了 CPE 的下界。在参考机上有如下数据:
| 整数 + | 整数 * | 浮点 + | 浮点 * | |
|---|---|---|---|---|
| 延迟 | 1 | 3 | 3 | 5 |
| 吞吐量 | 0.5 | 1 | 1 | 0.5 |
浮点乘吞吐量反而低是因为浮点加只有一个功能单元(2),而浮点乘有两个(1,2),可以并行起来。
考察下面的例子:
用 Horner’s rule 计算多项式单点求值的代码
1 | double polyh(double a[], double x, long deg) { |
第 4 行的运算前后之间相互依赖,CPE 为 浮点乘 - 浮点加,其 CPE 为 8 左右。而
1 | double polyh(double a[], double x, long deg) { |
仔细考察依赖关系,发现 a[i] * xpwr 的结果和 result 的计算在相邻周期之间是没有依赖关系的,换言之在 result 进行加法时,可以继续算下一轮的 a[i] * xpwr。但是 xpwr = x * xpwr 在循环间有依赖关系,总的来说关键路径应该是 xpwr 的浮点数乘法链。其 CPE 仅为 5。
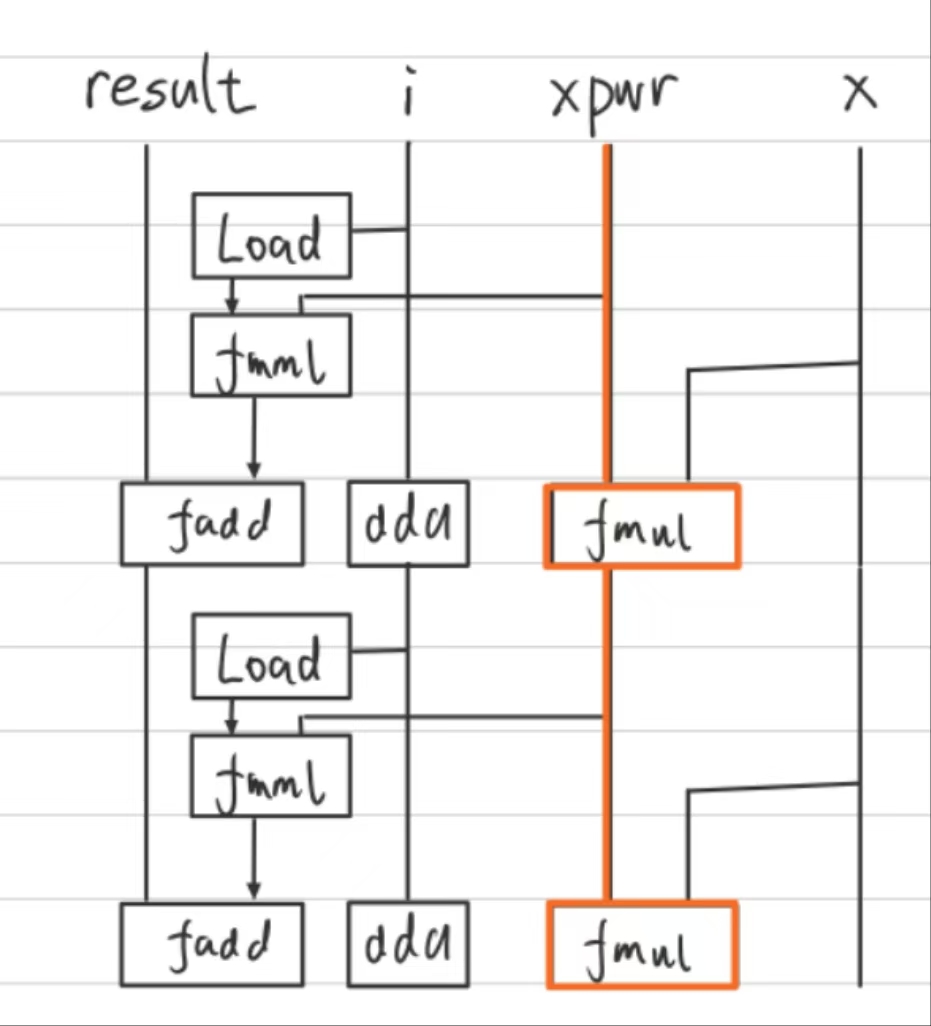
循环展开
简单考虑如下计算累加、累乘(标记为 OP)的循环
1 | for(int i = 0; i < len; i++) |
我们介绍几种循环展开技术
$2\times 1$ 展开
1
2for(int i = 0; i < len; i += 2)
acc = (acc OP data[i]) OP data[i + 1];这种操作能够将循环体操作(
i++,比较i < len)等减少一次,如果OP运算是加法,就可以将关键路径从循环体操作(一次加法、一次比较)变成OP运算的链,从而将 CPE 压到加法的延迟。但是如果OP是乘法,那么关键路径一向是OP运算的链,CPE 始终是乘法的延迟。$2\times 2$ 展开
1
2
3for(int i = 0; i < len; i += 2)
acc1 = (acc1 OP data[i]), acc2 = (acc2 OP data[i + 1])
acc = acc1 OP acc2发现
acc1和acc2能够并行计算。关键路径还是需要分加法乘法讨论(循环体开销是否更大)。$2\times 1a$ 展开 / 重结合
1
2for(int i = 0; i < len; i += 2)
acc = acc OP (data[i] OP data[i + 1]);关键路径的分析类似于上面多项式的例子。发现在乘法运算上后两种展开都达到了乘法的延迟的一半。
注意 $2\times 2$ 和 $2\times 1a$ 都需要运算满足结合律。
存储器层次结构
存储技术
RAM
| 实现 | 晶体管 / 位 | 相对访问时间 | 是否持续 | 是否敏感 | 相对花费 | 应用 | |
|---|---|---|---|---|---|---|---|
| SRAM | 双稳态元件 | $6$ | $1\times$ | 是 | 否 | $1000\times$ | 高速缓存 |
| DRAM | 小电容 | $1$ | $10\times$ | 否 | 是 | $1\times$ | 主存、帧缓冲区 |
DRAM 需要持续刷新或者使用纠错码(电容漏电)。
一个 DRAM 芯片上有 $w$ 个 DRAM 单元,每个单元被分为 $d = rc$ 个超单元(一个超单元是 1 位)。因此一个 DRAM 芯片上存 $d\times w$ 位的信息。
DRAM 单元内含一个行缓冲区,每次先将一行复制到缓冲区,然后取对应的列。
访存时由内存控制器发送 $(i, j)$ 依次称为行访问选通脉冲 RAS 和列访问选通脉冲 CAS,共用相同的地址引脚先后发送(设计成二维的可以降低引脚数目)。
一个 64 位的字被存储在 $8$ 个 $8\text{M}\times 8$ 的 DRAM 芯片上。
有一些增强的 DRAM
- 快页模式 DRAM(FPM DRAM) 发送一个 RAS 之后可以连续发送 CAS。
- 扩展数据输出 RAM(EDO RAM) 比 FPM RAM 能够容许时间上靠得更紧密的 CAS。
- 同步 DRAM(SDRAM) 内存控制器和 RAM 使用相同的时间信号,只需知道结果上来讲比异步的存储器更快。
- 双倍数据速率同步 DRAM(DDR DRAM) 用两个时钟沿作为控制信号,使速率翻倍。按照预取缓冲区大小分为 DDR(2 位)、DDR2(4 位)、DDR3(8 位)。
- 视频 RAM(VRAM) 用于图形系统的帧缓冲区。输出通过依次对内部缓冲区进行移位得到、允许并行读写。
现在的 Core i7 只支持 DDR3.
后面不想看了。
高速缓存
局部性
时间局部性 指一个内存位置被引用则很可能在不远的将来被多次引用。
空间局部性 指一个内存位置被引用则很可能在不远的将来引用附近的一个位置。
注意存储器上当步长为 1,无论大小如何变化吞吐量都是 12GB/s,这是因为 Core i7 存储器系统有预取机制,会在提前取要访问的元素。
缓存不命中
分为冷不命中、冲突不命中、容量不命中。注意后两者有区别,冲突不命中是指缓存本身足够大,但是因为映射策略的问题会始终将两个元素打到同一个位置,于是一直不命中。
写策略
写命中时
- 直写 继续往下写下一级的副本。
- 写回 在被驱除时才写给下一级。
写不命中时
- 写分配 将块从下面拉上来然后写入。
- 非写分配 继续往下找。
通常情况下时直写配非写分配,写回配写分配。